
|
DESIGNING EXPERIMENTS
Psychologists aren't consistent in their terminology: I've seen this called "experimental design" and "participant design" as well as "research design". Edexcel in the past has used all three terms.
“Design” refers to how the participants are assigned to different conditions of the IV in an experiment. Usually an experiment will have a control condition who behave normally in a normal environment and an experimental condition who are different in some way – they might have had something done to them or their environment might have been changed.
Design decisions are about who gets to take part in each condition: the same people or different people? INDEPENDENT GROUPS DESIGN
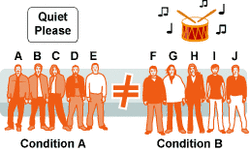
In an experiment with independent groups design, there are actually completely different groups of people in each condition of the IV and no one gets to be in more than one condition. This means that each participant only experiences the IV once.
This might be done when the researcher gets a sample together then splits them into two groups – perhaps by tossing a coin. One group becomes the experimental condition and the other group becomes the control condition.
Independent groups produces confounding variables because it’s very difficult to make sure that the two groups contain exactly similar people. It’s hard to be sure that the IV is the only difference between the groups. These differences are called participant variables. 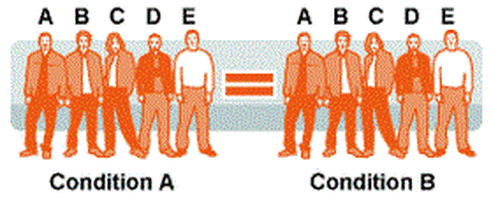
Participant variables are the main problem for independent groups design, because if the different groups aren't the same then the internal validity of the experiment is ruined.
Participant variables are always extraneous variables but they're not always confounding variables. Some participant variables just don't matter much. For example, in a memory experiment it probably doesn't matter what sign of the Zodiac each participant is; it's not like Leos or Capricorns have better memories. You don't need participants to be exactly identical, just similar in important respects. Another (lesser) problem is convenience. You need a lot more participants to carry out independent groups design: a complete set of people for each condition. That can be time-consuming and (if you are paying them to take part) expensive. REPEATED MEASURES DESIGN
Another approach is to take a single group of people and make sure they all experience both conditions. In repeated measures design everyone gets to be in the experimental condition and the control condition. In other words, they experience every condition of the IV.
This usually happens when you test people twice, at different times. For example, you could test students’ concentration levels before lunch then again after lunch. In many ways, repeated measures is the best sort of design. It uses fewer people (since you don’t need two separate groups) and – crucially – you know that the only difference between the experimental condition and the control condition is the IV, because they’re the same people. To put it another way, there are fewer participant variables. However, repeated measures can suffer from order effects. If you test the same group of people twice, then they might behave differently the second time because they’re familiar with the test – or bored with it. COMPARING INDEPENDENT GROUPS & REPEATED MEASURES
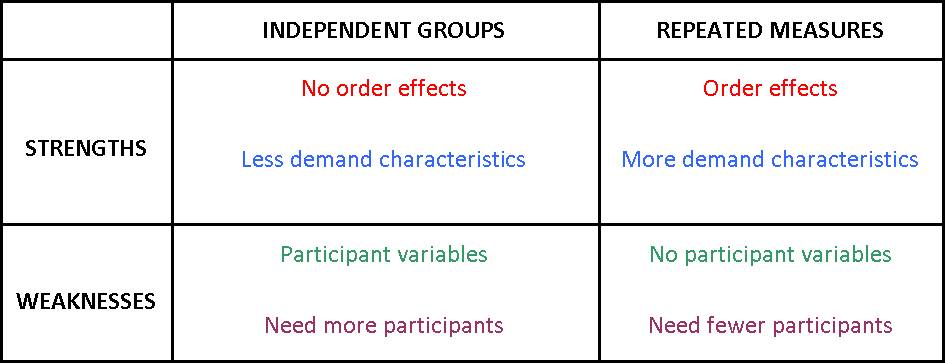
If you are paying attention, you'll have noticed that independent groups and repeated measures are opposites of each other: the strengths of one are the weaknesses of the other, and vice versa.
ORDER EFFECTS, RANDOMISATION & COUNTER-BALACING
The big disadvantage of repeated measures is order effects: a confounding variable introduced because the participants experience every condition of the IV.
As well as practice and/or fatigue, order effects also make it much more likely the participants will figure out the purpose of the experiment and that introduces demand characteristics: the participants behave unnaturally because they are trying to do what they think the researchers want them to do. You could get round order effects by just changing the test a bit each time. For example, you could use new words in a memory test. However, this means there are now situational variables at work and changes in the DV might not be solely due to the IV (the new words might be easier or harder to remember). This ruins the internal validity of the experiment. There are two better solutions to the problem of order effects:

Both these techniques reduce order effects because although some participants do better (or worse) by doing the control condition second, others do the experimental condition second and they cancel each other out.
However, you need a lot more participants in your study if you're going to split them into sub-groups like this and one of the advantages of repeated measures design was supposed to be that it didn't involve using as many participants as independent groups design. MATCHED PAIRS DESIGN
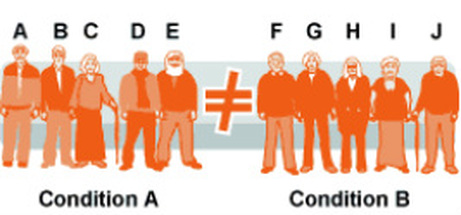
There is a "best of both worlds" option that combines the strengths of independent groups design (no order effects!) with the strengths of repeated measures (reduced participant variables!). This is matched pairs design.
Matched pairs starts out like regular independent groups design. Then you to “match” each person in the experimental condition with a similar person in the control condition. You could match people on their age, sex, IQ, social class or anything else that’s measurable. The "matching" reduces participant variables if it is successful. However, there are problems with this:
|
|
APPLYING RESEARCH DESIGN IN PSYCHOLOGY
|

|
EXEMPLAR ESSAY
|